Development processes in the GenAI era
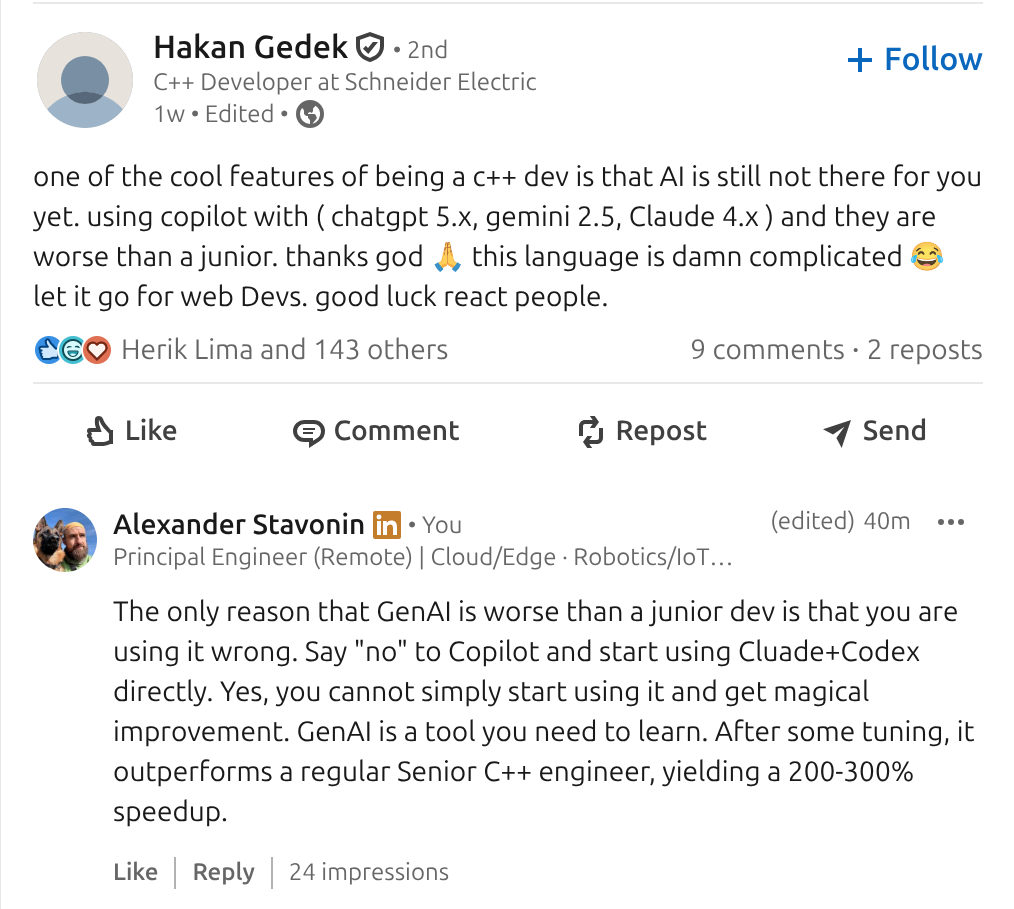
The current debate around GenAI and C++ is a good illustration of the real problem. Many engineers report that models are worse than juniors. Others report dramatic speedups on the same language and problem space. Both observations are correct.
The difference is not the model. It is the absence or presence of the state.
Most GenAI usage today is stateless. A model is dropped into an editor with a partial view of the codebase, no durable memory, no record of prior decisions, no history of failed attempts, and no awareness of long-running context. In that mode, the model behaves exactly like an amnesic junior engineer. It repeats mistakes, ignores constraints, and proposes changes without understanding downstream consequences.
When engineers conclude that “AI is not there yet for C++”, they are often reacting to this stateless setup.
At the same time, GenAI does not elevate engineering skill. It does not turn a junior into a senior. What it does is amplify the level at which an engineer already operates. A senior engineer using GenAI effectively becomes a faster senior, and a junior becomes a faster junior. Judgment is not transferred, and the gap does not close automatically.
These two facts are tightly coupled. In stateless, unstructured usage, GenAI amplifies noise. In a stateful, constrained workflow with explicit ownership and review, it amplifies competence.
This is why reported productivity gains vary so widely. Claims of 200–300% speedup are achievable, but only locally and only within the bounds of the user’s existing competence. Drafting, exploration, task decomposition, and mechanical transformation accelerate sharply. End-to-end throughput increases are lower because planning, integration, validation, and responsibility remain human-bound.
The question, then, is not whether GenAI is “good enough”. The question is what kind of system you embed it into.
Note
Everything I'll explain below is only applicable to the Stateful GenAI setup.






